Last week we started having problems with VCB Backups. Normally while a VCB backup job is in progress the VI Client will report that the VM tools is not running on the VM that's being backed up. When the VCB backup job completes, the status of the VMware Tools changes from "Not running" to OK.
However, I've seen cases where even after the VCB job completes, the VMware Tools status fails to change from "Not running" to "OK". If you then try to run a VCB job on the same VM, the job will fail if the VCBMounter is set to look for the virtual machine IP rather than virtual machine name or UUID.
I first noticed this problem on Monday, 16 March, but a couple of days later I found a VMware KB article dated 18 March 2009 which describes the exact same issue. The problem seems to be occurring only on hosts with patch bundle ESX350-200901401-SG. However, instead of offering a fix to the issue, VMware is only offering a few workarounds. I hope they release a patch to fix this issue soon.
Some workarounds given by VMware are:
- Restart the mgmt-vmware service immediately after the backup job is done. This changes the Tools status to OK. You can write a cron job to do it periodically.
OR - Log in and log out, or log out if you are already logged in, from the virtual machine. This changes the Tools status to OK if it was showing as Not running.
OR - Use VCBMounter to look for virtual machine name or UUID rather than virtual machine IP. Virtual machine IP only works when the status of tools is OK, but virtual machine name and UUID works even if the Tools status shows as Not running.
My preferred workaround:
I find that restarting the VMware Tools Service in the guest OS always gets by the problem, but loggin into every single VM that reports the wrong status for it's VMware Tools could be a bit of a drag. So I choose to do this remotely rather that logging on to each VM.
From any Windows workstation/server, open a command pompt and run:
sc \\{vm-name-or-ip-address} stop "VMTools"
sc \\{vm-name-or-ip-address} start "VMTools"
Information on this issue can be found on the VMware Knowledge Base article: KB1008709
Today I had an issue here an ESX host became unresponsive in vCenter, yet the VMs that were running on the host were fine. The normal remedy for this issue would be to restart the management agent on the ESX host via the Service Console:
/etc/init.d/mgmt-vmware restart
However, this did not work. The mgmt-vmware restart command hung while stopping the "VMware ESX Server Host Agent". Ten minites after executing mgmt-vmware restart, I decided to break out of the process by pressing Ctrl+z.
Clearly, there was a problem with the existing running instance of the management agent, vmware-hostd. The only way to get this working without a host reboot, is to find the PID for vmware-hostd and kill it:
To locate the PID for the running vmware-hostd process execute:
ps -auxwww |grep vmware-hostd
You will see output similar to: (I've marked the PID in BOLD text)
root 13089 1.3 2.6 179080 6988 ? S 2008 1695:23 /usr/lib/vmware/hostd/vmware-hostd /etc/vmware/hostd/config.xml -u
To kill the running process, execute:
kill -9 <PID> (I had to run "kill -9 13089")
Once vmware-hostd is no longer running, you can restart the management agent by running:
/etc/init.d/mgmt-vmware restart
-or-
service mgmt-vmware restart
Administrators that's got some experience in running Linux guest operating systems in virtual machines, may know that the time of the guest OS can drift by several hours per day. Normally, in my experience the time in the guest OS runs too fast. This can have serious implications on some services that these servers provide, such as Mail/Spam relays and web servers.
VMware has now released a very good KB article on best practises for Linux Guest OS time keeping, with a table of kernels and their parameters.
The KB article is a must read for those who have Linux guests. You can find VMware KB Article 1006427 here
I'm currently writing a document that I will publish soon on building a low cost lab with VI3. While I was doing some research on VMFS partition alignment, I found that I was unable to create (or delete) partitions on the /dev/sda disk that ESX is installed on. I could make the changes, but as I tried to write the changes to disk, fdisk would come back with the following error:
SCSI disk error : host 1 channel 0 id 0 lun 0 return code = be0000
I/O error: dev 08:00, sector 40355342
Device busy for revalidation (usage=8)
I know that I could just use the VI client to create this partition, but as I'm busy writing this fairly detailed document, I wanted to show potential readers how to create such an aligned local VMFS3 partition using fdisk and vmkfstools on the /dev/sda device.
Then I also had the question in my mind... "If the VI client can do it, why can't I?"
Anyway, after playing around with ESX a little, I found a fix. Use with caution though!
You need to remove the lock that ESX has on the device! The esxcfg-advcfg command can do this.
Before running fdisk, execute the following command at the service console:
esxcfg-advcfg -s 0 /Disk/PreventVMFSOverwrite
With PreventVMFSOverwrite now switched off, you can use fdisk to write the partition changes without the error. You will still get "device or resource busy" but it will write the changes.
After you have saved the partition changes using fdisk, run the following commands:
partprobe
esxcfg-advcfg -s 1 /Disk/PreventVMFSOverwrite
I've seen cases where a newly extended VMFS datastore fluctuates between the old size and the new size. Virtual Machines running on th newly extended datastore prevents the correct size of the datastore from displaying.
I found the solution to the problem in KB Article 1002558
Products: VMware ESX and ESXi
The solution is:
- Shut down or VMotion virtual machines running on the extended datastore to the ESX host that created the extent.
- On all other ESX hosts other than the one that created the datastore, run vmkfstools -V to re-read the volume information.
- Power on or VMotion the Virtual Machines back to the original ESX hosts.
This is not only on VI3 hosts but on:
VMware ESX 2.0.x
VMware ESX 2.1.x
VMware ESX 2.5.x
VMware ESX 3.0.x
VMware ESX 3.5.x
VMware ESXi 3.5.x Embedded
VMware ESXi 3.5.x Installable
Now this may be old news, but I decided to blog it anyway for my own reference.
Simon Long has written a good article on how to improve VMotion performance when performing mass migrations. This is very handy when you are putting a host into maintenance mode. Thanks to Jason Boche for blogging it first!
I'll set the scene a little...
I’m working late, I’ve just installed Update Manager and I‘m going to run my first updates. Like all new systems, I’m not always confident so I decided “Out of hours” would be the best time to try.
I hit “Remediate” on my first Host then sat back, cup of tea in hand and watch to see what happens….The Host’s VM’s were slowly migrated off 2 at a time onto other Hosts.
“It’s gonna be a long night” I thought to myself. So whilst I was going through my Hosts one at time, I also fired up Google and tried to find out if there was anyway I could speed up the VMotion process. There didn’t seem to be any article or blog posts (that I could find) about improving VMotion Performance so I created a new Servicedesk Job for myself to investigate this further.
3 months later whilst at a product review at VMware UK, I was chatting to their Inside Systems Engineer, Chris Dye, and I asked him if there was a way of increasing the amount of simultaneous VMotions from 2 to something more. He was unsure, so did a little digging and managed to find a little info that might be helpful and fired it across for me to test.
After a few hours of basic testing over the quiet Christmas period, I was able to increase the amount of simultaneous VMotions…Happy Days!!
But after some further testing it seemed as though the amount of simultaneous VMotions is actually set per Host. This means if I set my vCenter server to allow 6 VMotions, I then place 2 Hosts into maintenance mode at the same time, there would actually be 12 VMotions running simultaneously. This is certainly something you should consider when deciding how many VMotions you would like running at once.
Here are the steps to increase the amount of Simultaneous VMotion Migrations per Host.
1. RDP to your vCenter Server.
2. Locate the vpdx.cfg (Default location “C:\Documents and Settings\All Users\Application Data\VMware\VMware VirtualCenter”)
3. Make a Backup of the vpdx.cfg before making any changes
4. Edit the file in using WordPad and insert the following lines between the <vpdx></vpdx> tags;
<ResourceManager>
<maxCostPerHost>12</maxCostPerHost>
</ResourceManager>
5. Now you need to decide what value to give “maxCostPerHost”.
A Cold Migration has a cost of 1 and a Hot Migration aka VMotion has a cost of 4. I first set mine to 12 as I wanted to see if it would now allow 3 VMotions at once, I now permanently have mine set to 24 which gives me 6 simultaneous VMotions per Host (6×4 = 24).
I am unsure on the maximum value that you can use here, the largest I tested was 24.
6. Save your changes and exit WordPad.
7. Restart “VMware VirtualCenter Server” Service to apply the changes.
Now I know how to change the amount of simultaneous VMotions per Host, I decided to run some tests to see if it actually made any difference to the overall VMotion Performance.
I had 2 Host’s with 16 almost identical VM’s. I created a job to Migrate my 16 VM’s from Host 1 to Host 2.
Both Hosts VMotion vmnic was a single 1Gbit nic connected to a CISCO Switch which also has other network traffic on it.
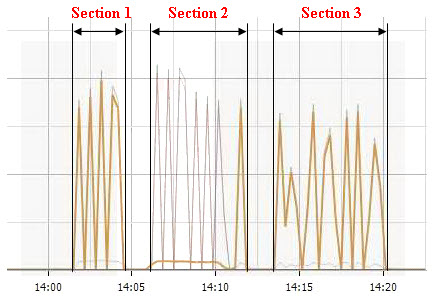
The Network Performance graph above was recorded during my testing and is displaying the “Network Data Transmit” measurement on the VMotion vmnic. The 3 sections highlighted represent the following;
Section 1 - 16 VM’s VMotioned from Host 1 to Host 2 using a maximum of 6 simultaneous VMotions.
Time taken = 3.30
Section 2 - This was not a test, I was simply just migrating the VM’s back onto the Host for the 2nd test (Section 3).
Section 3 - 16 VM’s VMotioned from Host 1 to Host 2 using a maximum of 2 simultaneous VMotions.
Time taken = 6.36
Time Different = 3.06
3 Mins!! I wasn’t expecting it to be that much. Imagine if you had a 50 Host cluster…how much time would it save you?
I tried the same test again but only migrating 6 VM’s instead of 16.
Migrating off 6 VM’s with only 2 simultaneous VMotions allowed.
Time taken = 2.24
Migrating off 6 VM’s with 6 simultaneous VMotions allowed.
Time taken = 1.54
Time Different = 30secs
It’s still an improvement all be it not so big.
Now don’t get me wrong, these tests are hardly scientific and would never have been deemed as completely fair test but I think you get the general idea of what I was trying to get at.
I’m hoping to explore VMotion Performance further by looking at maybe using multiple physical nics for VMotion and Teaming them using EtherChannel or maybe even using 10Gbit Ethernet. Right now I don’t have the spare Hardware to do that but this is definitely something I will try when the opportunity arises.


